

Machine Learning
Machine Learning 이란 어떠한 것의 성능을 향상시키기 위해 경험에 근거해서 발전시키는 알고리즘이다.
예를 들어, 체스 게임을 하는 프로그램이 많이 이기기 위한 Machine Learning 알고리즘이 존재한다고 가정해보자.

여기서 행위를 세 가지로 분류할 수 있음.
T (Task) : 체스를 하는 행위
P (Performance) : 상대방을 이길 수 있는 확률
E (Experience) : 스스로 체스 게임을 하는 것
체스 게임을 반복하면서 그 수를 놓은 데이터들을 가지고 학습하여 이길 수 있는 수들을 산출하는 것.
Traditional Programming 은 다음과 같이 결과를 산출하였음.
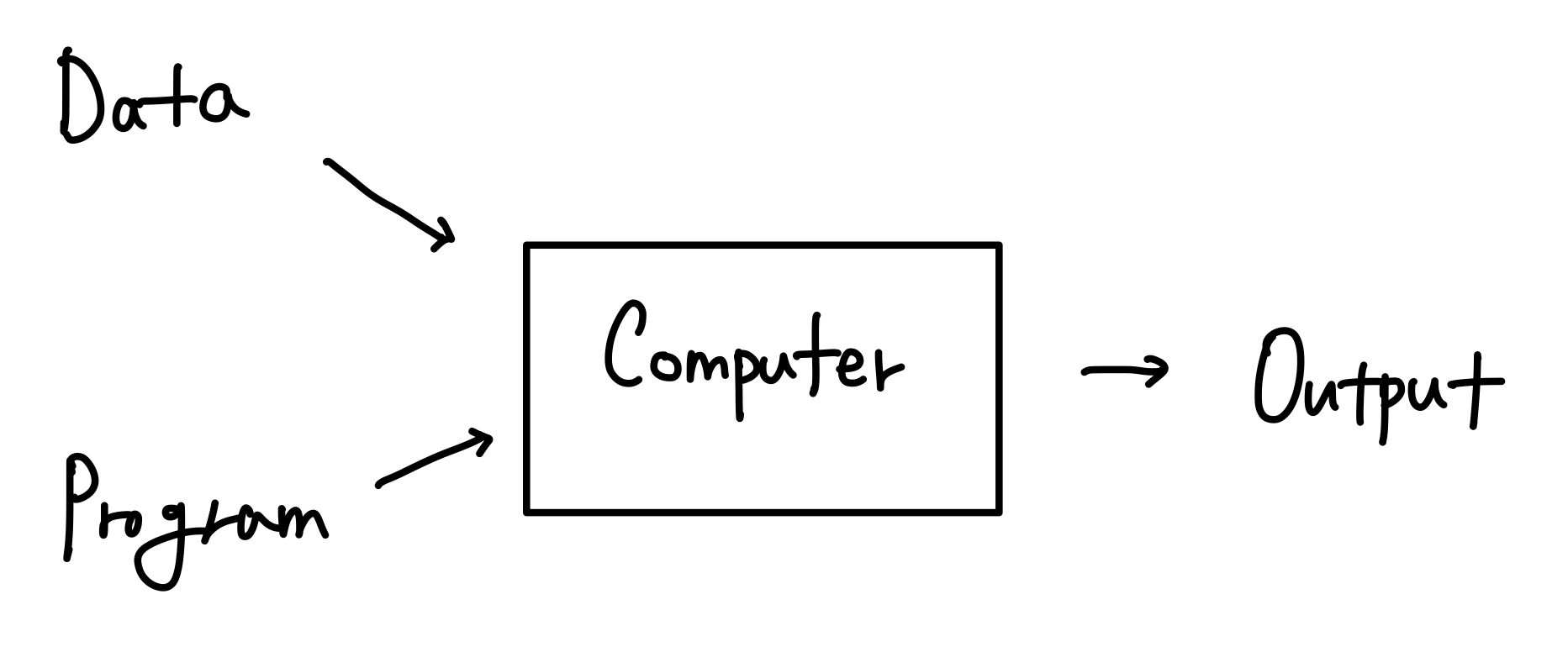
그러나, Machine Learning 에서는 다르게 결과가 산출됨.

예를 들어, "Spell checker" 를 해주는 프로그램이 존재한다고 한다면 다음과 같은 과정을 거쳐서 결과가 산출됨.

Machine Learning 에서의 가장 중요한 개념은 바로 "Generalization"
Generalization
- 공통된 특성을 공식화하는 추상화의 한 형태
- 데이터를 생성하는 프로세스의 통계 모델을 구축
단, ML 에서 주의해야 할 부분이 존재함.
"No Free Lunch Theorem for ML"
즉, ML Algorithm 이 보편적으로 뭐가 더 낫다는 건 없다는 의미임 (절대적으로 좋은 ML Algorithm 은 존재하지 않음)
Machine Learning 에서 학습하는 방법에는 크게 4가지가 존재함.
- Supervised Learning
- Unsupervised Learning
- Semi-supervised learning
- Reinforcement learning
하지만 주로 Supervised Learning 을 사용한다. 이번 포스팅에서는 지도 학습을 주로 다룰 예정이며 강화 학습은 따로 다루지 않을 것.
Supervised Learning
지도 학습은 학습 데이터가 있고, 정답이 존재하는 데이터가 있는 학습 방법이다.
학습 데이터와 정답 데이터를 가지고 학습시켜서 데이터만 넣어주면 정답이 도출될 수 있도록 하는 알고리즘이다.
Output 으로 산출되는 데이터, 또는 문제는 두 가지가 존재한다.
1. Classification
정답으로 주어지는 y가 "categorical", 즉 분류가 되는 알고리즘이다.
예를 들면 아래 그림과 같이 Class 를 분류하려고 할 때 Class A 와 Class B 를 나누기 위해 y를 1과 0으로 맞출 수 있다.

2. Regression
정답 데이터 y가 연속적인 값을 가지는 경우인데, 확률적인 이야기를 할 때 사용된다.

Unsupervised Learning
학습 데이터는 있지만 정답이 있는 데이터가 같이 주어지지 않는 학습 방법이다.
예를 들면 100명의 사람들이 존재하는데, 비슷한 성질을 가진 사람들을 3 종류로 나누려고 하는데 그 기준이 없다.
그래서 특성들을 종합적으로 파악해서 그 기준을 세워서 나누는 것이다.
위의 경우를 Clustering 이라고 하는데, Unsupervised Learning 은 anomaly detection, density estimation 등 여러 가지로 나뉜다.

Semi-supervised Learning
Supervised Learning 과 Unsupervised Learning 를 섞은 학습 방법으로, Labeling 된 데이터, 즉 정답이 있는 데이터가 적고 Unlabeled 된 데이터가 많으면 사용할 수 있는 학습 방법이다.
위의 경우는 LU learning 이라고 한다.
Positive data 와 Unlabeled data 가 존재하는 경우, 즉 Negative 한 데이터는 라벨링이 되지 않은 경우 Semi-supervised Learning 방법을 사용할 수 있는데, 이러한 경우를 PU learing 이라고 한다.
Reinforcement Learning
시행착오를 겪으면서 학습하는 방법으로, 학습 시스템과 환경 사이에서 계속해서 보상을 통해 학습하는 방법이다.
안좋은 방법이라고 판단되면 보상을 적게 주고, 좋은 방법이면 보상을 더 줌으로써 Agent, 즉 프로그램이 스스로 좋은 방법을 찾아갈 수 있도록 하는 학습 방법이다.

Bias and Variance
Machine Learning 을 하는 목적은 결국 스스로 학습해서 "정답" 을 찾기 위함이다.
그 정답을 잘 찾기 위해서는 정답일 확률이 가장 높아지게 만드는 Weight (Variance)와 Bias 를 찾아야 한다.
위에 대한 설명은 생략하도록 하겠다.
그래서, function class (Data point 가 속할 수 있는 범주) 를 정의하는 것이 매우 중요하다.
Weight와 Bias 를 최대로 만들기 위해 어떤 함수가 제일 정답 function 에 근접하는 것을 평가하는 Metric 인 "Loss function" 을 정의하는 것도 ML 에서 매우 중요하다.


그렇다면, 정답에 가까워질 정확성을 높이기 위해서는 ML Algorithm 에 들어가는 함수, 즉 Weight 과 Bias 를 최적화하는 함수를 찾아야 한다. 그러나, 함수를 너무 최적화한다면 Overfitting 문제가 발생할 수 있다.
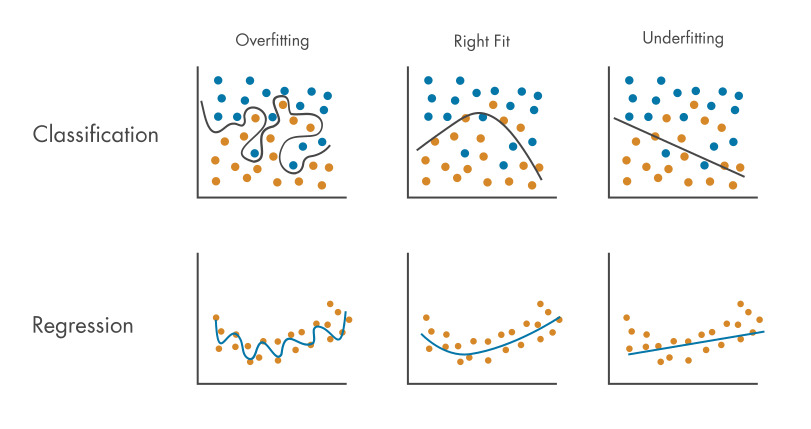
우리는 Data를 총 3가지로 분류할 수 있다.
- Train Data
- Test Data
- Validation Data
여기서 말하는 Train data 와 Validation Data 는 이미 검출된 입력할 데이터이다.
일반적으로는 80% 정도 Train data 로 사용하고, Validation Data 는 20% 정도 사용한다.
Test data 는 관찰되지 않은 데이터로, 학습이나 검증에 사용되지 않은 데이터로만 이루어져야 한다.
Data는 모두 아래와 같은 규칙을 지켜야 한다.
iid (independent and identically distributed)
모든 나올 수 있는 경우를 확률로 정의하자면 P(x, y) 로 표현된다.
입력값인 x를 넣으면 정답인 y가 나올 확률이다.
위에서 언급했듯이 Machine Learning 에서 가장 중요한 것은 Generalization, 즉 일반화 이다.
Underfitting 이 되었다는 것은 학습 데이터가 충분하지 않게 학습이 되었다는 의미이므로, 아예 학습을 하지 않은 것과 같다.
따라서, ML Algorithm 을 학습시킬 때 다음과 같은 순서로 진행하는 것이 좋다.
- 학습 과정에서의 에러를 최소한으로 줄인다.
- 학습과 테스트 에러 사이의 차이를 줄인다.
Capacity and Error
Capacity란 모델의 복잡성이다.
Capacity 를 늘릴 경우, Training error 는 감소하지만 Training error 와 Generalization error 와의 gap 은 더욱 커진다.
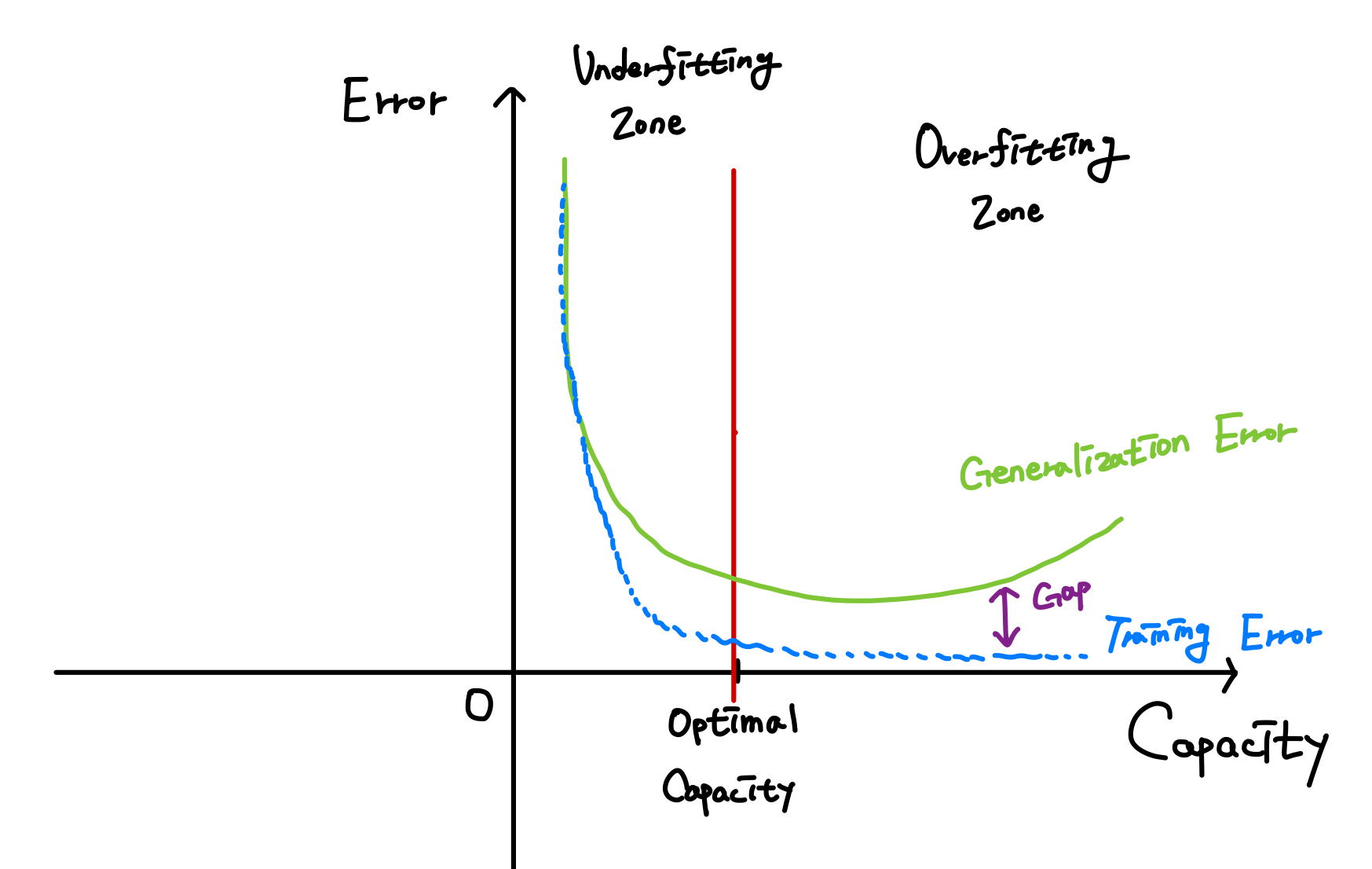
Regularization
- Generalization Error 를 줄이기 위해 사용됨. (Training error 를 줄이는 것이 아님)
- 람다 값에 따라 Weight 값들의 크기를 변경하여 모델의 복잡도를 조정함.

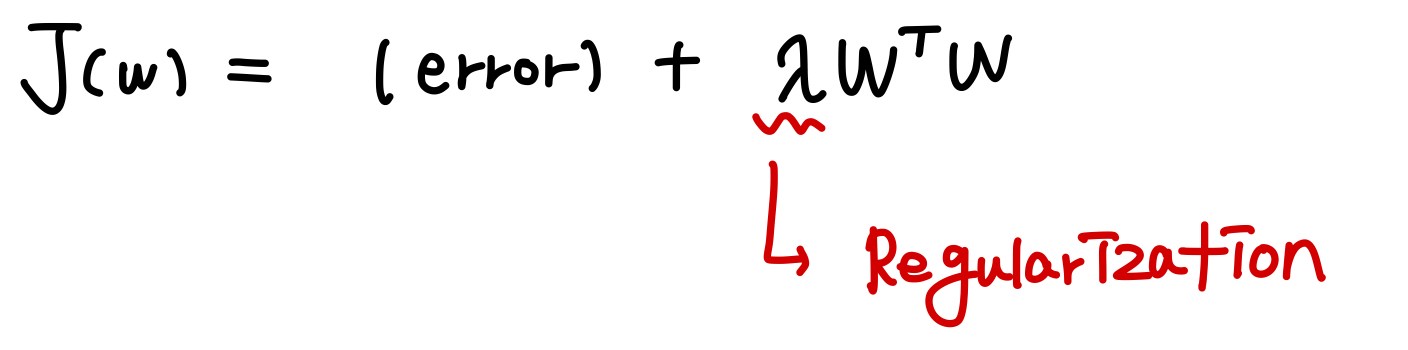
Bias/Variance Trade-off
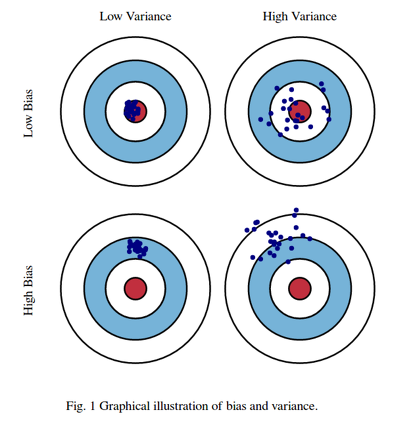
- Bias 가 낮으면 예측이 잘 된 것.
- Variance 가 낮으면 안정적임.
- Capacity 가 증가하면 Variance 는 증가하고, Bias 는 감소하는 경향이 있음.
- Variance 가 높으면 Overfitting 일 가능성이 높음.
- Bias 가 높으면 Underfitting 일 가능성이 높음.
'Data Engineer > AI' 카테고리의 다른 글
| FastAPI 시작하기 (1) | 2024.11.23 |
|---|---|
| DeepFace Recognition (2) | 2024.11.22 |
| AI - 국민청원 분류 (0) | 2024.11.17 |
| AI - 작물 잎 사진으로 질병 분류 (3) | 2024.11.16 |
| AI - Pytorch (6) | 2024.11.14 |