

출처 : "한 줄씩 따라 해보는 파이토치 딥러닝 프로젝트" (이경택, 박희경, 전종섭, 김수지, 신훈철, 조민호, 이승현, 심은선, 장예은)

이미지 분류 모델을 활용하여 작물 잎 사진의 종류와 질병 유무를 판단하는 Project
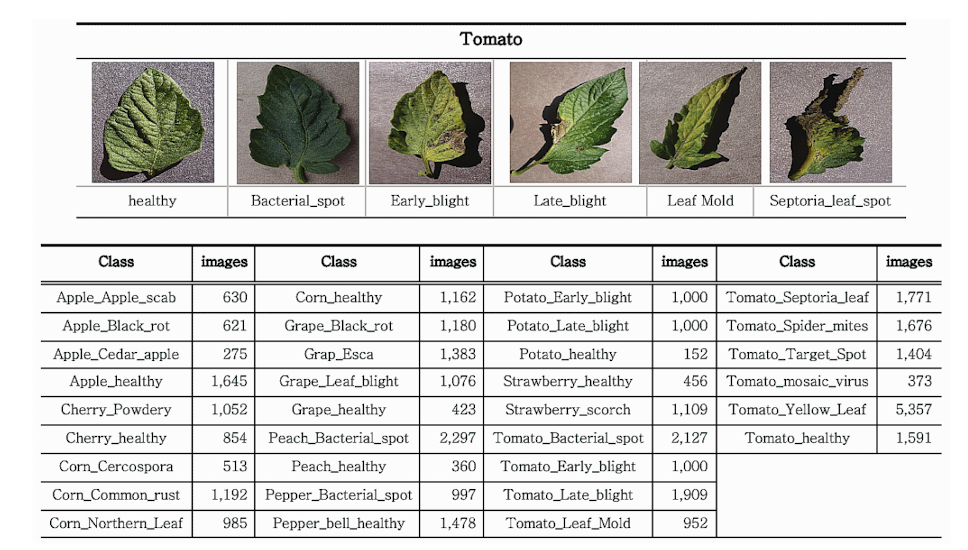
Project 에서 사용하는 총 데이터의 수는 40,000개 이고 분류 클래스와 각 클래스에 해당하는 데이터 수는 밑에 그림과 같음.
기본적인 BaseLine Model 모델을 구축 vs Pre-Trained Model 사용 (Transfer Learning 기법 사용) 후 비교!
- 데이터를 Train / Validation / Test 데이터로 나누고 각각의 클래스에 해당하는 폴더에 저장하는 작업을 시행하여야 함.
- Train Data : 모델을 훈련시키기 위한 용도
- Validation Data : 모델의 성능을 조정하기 위한 용도
- Test Data : 최종적으로 결정된 모델의 성능을 측정
import os
import shutil
original_dataset_dir = '/Users/b._.chan/Documents/TABA_Project/Leaf_practice/dataset' # 원본 데이터셋이 위치한 경로 지정
classes_list = [cls for cls in os.listdir(original_dataset_dir) if os.path.isdir(os.path.join(original_dataset_dir, cls))]
# os.listdir() : 해당 경로 하위에 있는 모든 폴더의 목록을 가져오는 메소드
base_dir = './splitted' # 나눈 데이터를 저장할 폴더 생성
os.mkdir(base_dir)
# 분리 후에 각 데이터를 저장할 하위 폴더 train, val, test create
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'val')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# train, validation, test 폴더 하위에 각각 클래스 목록 폴더 생성
for clss in classes_list:
os.mkdir(os.path.join(train_dir, clss))
os.mkdir(os.path.join(validation_dir, clss))
os.mkdir(os.path.join(test_dir, clss))
Transfer Learning
- 높은 성능의 Image 분류 모델을 구축하기 위해서는 많은 수의 질 좋은 Dataset이 필요
- 많은 경우에 이러한 Dataset을 구하기 어려우므로 대랑의 데이터셋으로 미리 학습된 모델을 재활용한 후, 일부를 조정하여 다른 주제의 이미지 분류에 사용하면 효과적!
- 대량의 데이터셋으로 미리 학습된 모델은 Pre-Trained Model 이며, 이를 조정하는 과정을 Fine-Tuning
- PyTorch 공식 문서에서도 torchvision.models 패키지를 통해 불러올 수 있는 모델의 종류와 각 모델에 관한 논문 정보 제공
- Deep Learning 모델을 설계하고 처음부터 학습을 진행할 때는 초기 Parameter의 값이 랜덤하게 설정됨.
- Transfer Learning을 할 때는 대량의 데이터로 미리 학습된 Parameter 값을 불러온 후 학습 과정에서 Update
- Fine-Tuning : 불러온 모델의 일부 Parameter 값 일부를 우리가 가진 데이터셋의 특성에 맞게 다시 학습하여 Parameter를 조정하는 것
- Pre-Trained Model의 일부 Layer는 학습 시에 Update 되지 않게 하고, 일부 Layer는 Update 되도록 설정하는데 이 과정에서 Parameter를 고정하는 것을 Layer Freeze 라고 함
- Image 분류 모델은 Low-Level Features 학습하고, 그걸 토대로 High-Level Features를 학습
- Low-Level Features : 작은 지역 패턴, High-level Features : Low-Level Features 구성된 더 큰 패턴
- 다른 종류의 이미지라도 낮은 수준의 특징은 상대적으로 비슷할 가능성 높음
- Fine-Tuning 과정에서 마지막 Layer인 Classifier와 가까운 Layer부터 원하는 만큼 학습 과정에서 Update
- Freeze 하는 Layer 수는 Dataset 크기와 Pre-trained Model 에 사용된 Dataset 과의 유사성 고려 결정

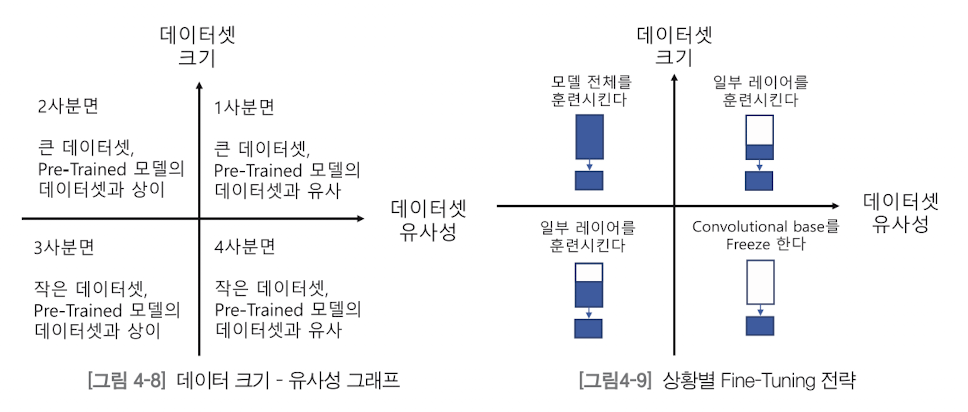
- Model 은 이미지의 Feature 를 학습하는 Convolutional Base 부분과 이미지를 분류하는 Classifier 부분으로 나뉠 수 있음
- 분류하는 이미지가 다를 경우 Classifier 부분을 변경
결론
BaseLine 초기 Parameter는 랜덤으로 설정되는 반면, Pre-Trained Model의 초기 Parameter는 수백만 장의 Image를 통해 미리 학습시켜놓은 모델의 Parameter 이므로 Pre-Trained Model이 더 좋은 성능을 나타낼 가능성이 높다는 것은 매우 당연한 사실!
Github : https://github.com/gratis-caelum/PyTorch_Project/blob/main/Leaf_practice/Leaf_Classifcation.ipynb
'Data Engineer > AI' 카테고리의 다른 글
| DeepFace Recognition (2) | 2024.11.22 |
|---|---|
| AI - 국민청원 분류 (0) | 2024.11.17 |
| AI - Pytorch (6) | 2024.11.14 |
| AI - DL (0) | 2024.11.12 |
| AI - ChatGPT API (Day 2) (4) | 2024.11.11 |