

Pytorch란?
- 딥러닝을 다루는 Library 중 하나
- Python의 언어 구조와 굉장히 유사하고 간결함
- 내부적으로 CUDA, cuDNN 이라는 API를 이용해 GPU 연산을 가능하게 하고 연산 속도가 월등히 빠름
- 2019년 중반 이후 부터는 Pytorch 구현 논문이 많아졌음 -> 위상이 높아짐
- 데이터의 형태로 Tensor를 사용한다는 점
Tensor
수학적인 개념의 "데이터의 배열"과 같음
0차원 - Scalar, 1차원 - Vector, 2차원 - Matrix, 3차원 이상 - n차원 Tensor (또는 초평면) 이라고 부름
Anaconda 설치
- Anaconda 는 선형 대수를 다루는 Numpy, 정형 데이터를 다루는 Pandas, 여러 머신러닝 알고리즘 모델이 포함된 Sklearn 등 기본 라이브러리를 제공
가상 환경 구축
- 여러 버전 라이브러리가 충돌하는 것을 방지하기 위해 독립된 작업 공간인 가상 환경을 구축하는 것을 추천함
conda create -n [가상 환경 이름] python=[version] # 가상 환경 구축
source activate [가상 환경 이름] # 생성한 가상 환경 활성화
source deactivate [가상 환경 이름] # 작업이 끝난 후 가상 환경 종료
PyTorch 설치
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
# 앞에서 구축한 가상환경을 활성화한 뒤 입력
손글씨 숫자 이미지 분류 문제
데이터 살펴보기
- MNIST data : 손으로 쓰인 0에서 9까지의 숫자로 이루어져 있음
- 각 이미지에는 어떤 숫자인지를 나타내는 정답 Label 정보가 포함
- Image Data : 0에서 1까지의 값을 갖는 고정 크기의 28 x 28 matrix
- 각 행렬의 원소는 픽셀의 밝기 정보를 나타냄 (1에 가까울 수록 흰색, 0에 가까울 수록 검은색)
- 레이블은 One-hot Encoding 방식으로 길이가 10인 벡터로 이루어져 있음
- MNIST는 눈으로 보기에는 2차원 행렬 데이터로 보이지만 실제로는 3차원 데이터
- 3차원 행렬은 [1, 28, 28]과 같은 형태이며 각각 [channel, Width, Height] 나타냄
- channel : 이미지를 구성하기 위한 색상 정보를 나타내고 색을 표현하는 차원
- 보통은 컬러 이미지는 Red, Green, Blue로 나타내는 RGB 3채널을 사용
- MNIST 데이터가 색상이 있는 이미지라면 28x28 행렬이 3개로 구성된 [3, 28, 28] 형태를 지님
CNN으로 손글씨 숫자 이미지 분류
코드는 크게 네 부분으로 구성됨.
- Module 및 분석 환경 설정
- 데이터 불러오기
- 모델 학습
- 모델 평가
Moduel 및 분석 환경 설정
- Python 코드를 작성할 때 필요한 모듈이 있는 경우 주로 코드 상단에 작성
import torch # Pytorch Library
import torch.nn as nn # DL Network의 기본 구성 요소를 포함한 torch.nn 모듈을 nn으로 지정
import torch.nn.functional as F # DL에 자주 사용되는 함수가 포함된 모듈
import torch.optim as optim # 가중치 추정에 필요한 최적화 알고리즘을 포함한 모듈
from torchvision import datasets, transforms # torchvision module : 딥러닝에서 자주 사용되는 데이터셋과 모델 구조 및 이미지 변환 기술 포함
from matplotlib import pyplot as plt # 데이터와 차트의 시각화 돕는 모듈
# GPU Acceleration Check If M series
if torch.backends.mps.is_available():
device = torch.device("mps")
print(torch.ones(1, device=device))
else:
print("MPS device no found")
데이터 불러오기
train_data = datasets.MNIST(root="./data", train= True, download=True, transform=transforms.ToTensor())
test_data = datasets.MNIST(root='./data', train = False, download=True, transform=transforms.ToTensor())
print("number of training data : ", len(train_data))
print("number of test data : ", len(test_data))- root : MNIST 데이터를 저장할 물리적 공간 위치로 './data' 는 현재 directory 위치의 data 라는 폴더 의미
- train : True/False의 논리값으로 데이터를 학습용으로 사용할 것인지를 지정
- download : True를 입력하면 root 옵션에서 지정된 위치에 데이터가 저장. 처음 시행이 아니고 이미 저장된 데이터가 있다면 False
- transform : MNIST 데이터를 저장과 동시에 전처리를 할 수 있는 Option. 이미지를 Tensor로 변형하는 전처리 transforms.ToTensor() 사용
- len 함수를 통해 학습 데이터는 60,000개, 테스트 데이터는 10,000개로 구성된 것을 확인
MNIST 데이터 확인
image, label = train_data[0]
plt.imshow(image.squeeze().numpy(), cmap = 'gray')
plt.title(f'label : {label}')
plt.show()
- image, label에 첫 번째 학습 데이터의 입력 데이터와 정답을 저장
- 3차원 Tensor를 2차원으로 줄이기 위해 image.squeeze() 사용 -> 크기가 1인 차원을 없애는 함수로 2차원인 [28, 28]로 만듦

Mini-batch 구성
train_loader = torch.utils.data.DataLoader(dataset=train_data,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data,
batch_size=batch_size,
shuffle=True)
first_batch = train_loader.__iter__().__next__()
print("{:15s} | {:<25} | {}".format('name', 'type', 'size'))
print("{:15s} | {:<25} | {}".format('Num of Batch', '', len(train_loader)))
print("{:15s} | {:<25} | {}".format('first_batch', str(type(first_batch)), len(first_batch)))
print("{:15s} | {:<25} | {}".format('first_batch[0]', str(type(first_batch[0])), first_batch[0].shape))
print("{:15s} | {:<25} | {}".format('first_batch[1]', str(type(first_batch[1])), first_batch[1].shape))
- torch.utils.data.DataLoader : 손쉽게 배치를 구성하며 학습 과정을 반복 시행할 때마다 Mini-batch를 하나씩 불러오는 유용한 함수
- dataset : Mini-batch로 구성할 데이터
- batch_size : Mini-batch의 size
- shuffle : 데이터의 순서를 랜덤으로 섞어서 Mini-batch를 구성할지 여부를 결정함. 시계열 데이터가 아닌 경우 딥러닝이 데이터의 순서에 대해서는 학습하지 못하도록 데이터를 랜덤으로 섞어주는 것이 필수
- DataLoader로 구성된 배치를 살펴보면 1,200개의 Mini-batch가 생성된 것을 알 수 있음 -> why? 60,000개의 학습 데이터에 50의 Batch_size를 사용했기 때문임.
- 배치의 첫 번째 요소 first_batch[0]은 [50, 1, 28, 28] 형태의 4차원 Tensor -> [Batch Size, channel, width, height]
- 데이터 한 개는 3차원이지만 데이터가 여러 개 쌓이면서 차원이 하나 더 늘어 4차원 Tensor가 됨.
- first_batch[1] : Mini-batch의 정답
모델 학습
- 모델을 만들기 위해서는 가장 먼저 클래스의 __init__을 통해 모델에 사용되는 가중치 형태를 정의
- 주의해야 할 점은 Layer를 쌓으면서 이전 Layer의 출력 크기와 직후 Layer의 입력 크기를 같게 설계하여야 함
- Channel의 크기는 Filter의 개수로 결정됨.
- Filter size(F), Stride size(S), Padding size(P)에 따라 출력되는 Feature Map의 사이즈(O) 공식에 의해 결정
- nn.Conv2d() function : padding=0과 stride=1을 기본값으로 사용하여 아래의 수식처럼 계산됨.

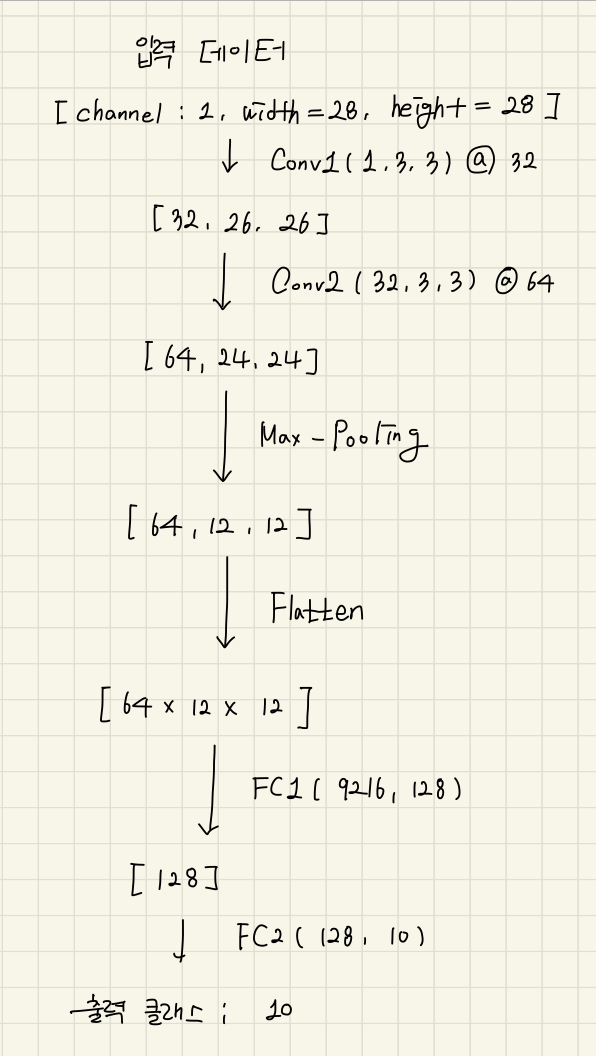
- MaxPooling 의 경우 Tensor의 가로, 세로에만 영향을 주므로 [64, 24, 24] 에서 [64, 12, 12]로 반감됨
- Flatten 연산은 Fully-connected Layer 연산을 위해 고차원 Tensor를 1차원으로 줄이는 것으로 3차원의 Tensor를 9,216 길이의 1차원 벡터로 변환
- Fully-connected Layer인 FC2에서는 각 출력 클래스의 분류 확률을 받기 위해 크기를 반드시 맞추어야 함
- MNIST는 0부터 9까지 10개의 클래스이기에 10의 길이로 구성됨
CNN 구조 설계
lass CNN(nn.Module): # nn.Module 클래스를 상속받는 CNN 클래스 정의
def __init__(self): # 모델에서 사용되는 가중치 정의
super(CNN, self).__init__() # super() 함수를 통해 nn.Module 클래스의 속성을 상속받고 초기화
self.conv1 = nn.Conv2d(1, 32, 3, 1) # 첫 번째 convolution Layer (in_channels : 입력 Tensor 채널 크기, out_channels : 출력 Tensor 크기로 conv2의
# in_channels와 같아야 함, kernel_size : Filter (3x3) , stride : Filter가 움직이는 단위, padding은 지정하지 않았으므로 시행 x)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128) # 첫 번째 fully-connected Layer (in_features = 9216, out_features = 128 : 9,216 size vector를 128 size
# vector로 변환하는 가중치 설계)
self.fc2 = nn.Linear(128, 10) # MNIST class 개수인 10 크기의 vector로 변환하는 가중치 설계
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1) # FC를 통과하기 전 고차원의 vector를 1차원의 vector로 변환,, -> 64 x 12 x 12 = 9,216
x = self.fc1(x) # 9,216 -> 128
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x) # 128 -> 10
output = F.log_softmax(x, dim = 1) # softmax 함수보다 연산 속도를 높일 수 있음
return output
Optimizer 및 Loss Function Define
model = CNN().to(device) # CNN Class를 통해 model 이라는 Instance 생성
optimizer = optim.Adam(model.parameters(), lr = learning_rate) # Loss function 최소로 하는 가중치를 찾기 위해 Adam Algorithm's Optimizer 지정
criterion = nn.CrossEntropyLoss() # 다중 클래스 분류 문제이기에 Cross-Entropy Loss function 지정
설계한 CNN 모형 확인
print(model)CNN(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(dropout1): Dropout2d(p=0.25, inplace=False)
(dropout2): Dropout2d(p=0.5, inplace=False)
(fc1): Linear(in_features=9216, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
모델 학습
model.train() # CNN Class가 저장된 model instance를 학습 모드로 실행
i = 0 # 반복 학습 중 손실 함수 현황을 확인하고자 학습 횟수를 나타내는 보조 Index 지정
for epoch in range(epoch_num): # 미리 지정해 둔 Epoch 수 만큼 반복 학습 for문 지정
for data, target in train_loader: # 학습 데이터를 batch_size로 나눈 만큼 반복 수행되고, train_loader 는 매 시행마다
# Mini-batch의 데이터와 정답을 data와 target에 지정
data = data.to(device) # Mini-batch의 데이터를 기존에 저장한 장비 device에 할당
target = target.to(device) # Mini-batch의 정답을 기존에 지정한 장비 device에 할당
optimizer.zero_grad() # 학습을 시작하기 전, 이전 반복 시행에서 저장된 Optimizer의 Gradient 초기화
output = model(data) # Mini-batch data를 모델에 통과시키는 Feed-Forward 연산으로 결과값 계산
loss = criterion(output, target) # 계산된 결과값과 실제 정답으로 Loss Function 계산
loss.backward() # Loss Function을 통해 Gradient 계산
optimizer.step() # 위에서 계산된 Gradient를 통해 모델의 가중치 Update
if i % 1000 == 0:
print('Train Step : {}\tloss : {:.3f}'.format(i, loss.item()))
i += 1
모델 평가
model.eval() # 평가 모드를 실행하기 위해 명시,, Dropout이 허용되지 않고 Batch-normalization 도 평가 모드로 전환
correct = 0 # 정답 개수를 저장할 correct 초기화
for data, target in test_loader: # Test data를 batch_size로 나눈 만큼 반복 수행되며, test_loader는 매 시행마다
# Mini-batch의 데이터와 정답을 data와 target에 저장
data = data.to(device) # Mini-batch data를 기존에 지정한 장비 device에 할당
target = target.to(device) # Mini-batch 정답을 기존에 지정한 장비 device에 할당
output = model(data) # Mini-batch data를 모델에 통과시켜 결과값 계산
prediction = output.data.max(1)[1] # Log-softmax 값이 가장 큰 index를 예측값으로 저장
correct += prediction.eq(target.data).sum() # 실제 정답과 예측값이 같으면 True, 다르면 False인
# 논리값으로 구성된 vector를 더함. 즉, Mini-batch 중 정답의 개수를 구하고 반복 시행마다 누적해서 더함
# 전체 Test-data 중 맞춘 개수의 비율을 통해 정확도를 계산하여 출력,,
print("Test set Accuracy : {:.2f}%".format(100 * correct / len(test_loader.dataset)))'Data Engineer > AI' 카테고리의 다른 글
| AI - 국민청원 분류 (0) | 2024.11.17 |
|---|---|
| AI - 작물 잎 사진으로 질병 분류 (3) | 2024.11.16 |
| AI - DL (0) | 2024.11.12 |
| AI - ChatGPT API (Day 2) (4) | 2024.11.11 |
| AI - ChatGPT API (Day 1) (4) | 2024.11.10 |