

Deep Learning
| 머신러닝 | 딥러닝 | |
| 활용 데이터 형태 | 정형 데이터 | 비정형 데이터 |
| 데이터 의존도 | 데이터가 적어도, 적정 수준의 성능 확보 가능 | 데이터가 적으면, 성능이 좋지 않음 |
| 하드웨어 의존도 | 저사양 하드웨어에서 실행 가능 | 고사양 하드웨어(GPU) 필요 |
| 설명력 | 회귀분석, 의사결정 나무 등 설명력이 강점인 방법론이 있음 | 모델 내부 연산 논리에 대해 추론이 어려움 |
| 문제 해결 방법 | 분석가가 임의로 문제를 여러 단계로 나누어 해결 | End-to-End 방식으로 입력부터 출력까지 분석가의 개입 없이 가능 |
| 특징(Feature) 추출 | 도메인 지식 또는 분석가의 의견이 반영되어 생성(Feature Engineering) | 딥러닝 네트워크 내부에서 스스로 학습(Feature Extraction) |
- 비정형 데이터의 경우 일반적으로 높은 차원의 형태
- 차원이 높은 만큼 모델을 잘 학습시키기 위해서는 대용량 데이터가 필수이며 딥러닝은 내부가 복잡하고 연산량이 많기 때문에 고사양 하드웨어가 필요
딥러닝 발전 과정
- 뇌의 기본 단위인 뉴런의 역할을 하는 Perceptron
- 데이터를 입력 받아 가중치와 입력값을 조합하여 다음 퍼셉트론으로 전달하는 구조
- 인공신경망은 퍼셉트론 여러 개가 모여 복잡한 업무를 수행하는 네트워크 구조라고 할 수 있으며 딥러닝은 인공신경망을 더 크고 깊게 확장한 것

- Activation Function은 뉴런처럼 합산된 신호 값을 활성화시켜 다음 퍼셉트론으로 넘겨줄 것인지를 결정
- 가장 간단한 활성 함수는 합산된 신호 값이 특정 임계치보다 크면 1을 출력하고, 아니면 0을 출력하는 Step Function
- 퍼셉트론은 간단한 선형 분류 문제만 풀 수 있는데, 복잡한 문제를 해결하기 위해 MLP(Multi-Layer Perceptron) 사용
Multi-Layer Perceptron
- Input Layer : 입력 데이터를 받는 Layer
- Hidden Layer : 이전 Layer 의 출력과 가중치 곱의 합을 입력받음으로써 Activation Function이 적용된 Layer
- Output Layer : 다층 퍼셉트론에서 최종 결과를 얻는 Layer

- 입력층은 입력 변수의 개수만큼, 출력층은 예측 변수의 개수만큼의 Node를 가짐
- 은닉층의 각 Node 에서 퍼셉트론 연산이 적용되기 때문에 다층 퍼셉트론에서 Layer와 Node 수가 증가할수록 더욱 복잡한 문제를 풀 수 있음
- 다층 퍼셉트론은 Feed Forward, Back Propagation을 반복하면서 가중치를 추정
- 입력층에서 출력층의 방향으로 연산하는 것을 Feed Forward
- 출력층에서 입력층의 방향으로 오차를 줄일 수 있게 가중치를 조정하는 과정을 Back Propagation
- 갖고 있는 모든 데이터에 대해 Feed Forward와 Back Propagation을 한 번씩 진행한 것을 Epoch
인공신경망 핵심 알고리즘
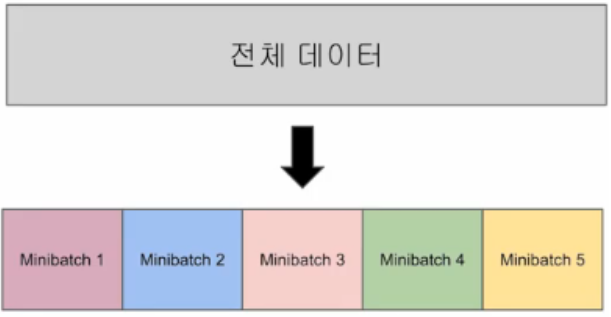
Mini-Batch
- 데이터가 클수록 계산량이 많아지고 하드웨어의 메모리 한계 -> Mini Batch 사용
Gradient Descent Method
- Back Propagation 과정에서 오차를 줄이는 방향으로 가중치를 업데이트하는 방식
- Loss function의 위치에서 가장 기울기가 가파른 방향으로 학습 Parameter를 Update
- Learning Rate는 임의로 정하는 Hyperparameter로서 너무 작게 설정한 경우에는 Local Mininum에 빠져 최적의 가중치를 얻지 못할 수 있음
- 너무 크게 설정하면 Overshooting 되어 Loss function이 발산하므로 학습이 이루어지지 않을 수 있음

- Gradient에 Learning Rate를 곱해 원래 가중치에서 빼면서 가중치를 조정하는 것으로 해석
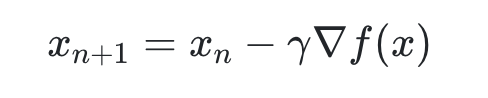
- Global Mininum Loss function 의 가중치를 원함
- Adam(Adaptive Moment Estimation) 방법을 많이 사용함
Activation Function
- 인공신경망이 성능이 좋은 이유 중 하나는 Non-Linear Function을 사용하기 때문임.
- 인공신경망의 성능을 향상시키기 위해서는 여러 개의 은닉층을 추가
- 여러 은닉층의 효과를 보기 위해서는 Non-Linear Function을 사용하여야 함.
- Perceptron 은 특정 임계치 이상이 되면 신호가 전달되는 Step Function을 사용했지만, 인공신경망에서는 가중치를 찾는 과정에서 미분이 필요하므로 임계치 부분에서 미분이 불가능한 Step Function 사용 불가
- Sigmoid Function을 도입했지만, Gradient Vanishing 문제 발생

- 많은 연구에서는 Gradient Vanishing 극복하고자 미분 가능한 여러 Activation Function 사용 -> ReLU, ELU 등의 함수 사용
Output Function
- 출력 함수는 마지막 출력층의 결과를 목적에 맞는 적절한 형태로 변형해주는 역할
- 회귀 문제이면 입력값을 그대로 출력하는 Identity Function, 분류 문제면 Softmax Function을 사용
- Softmax Function 은 입력값을 0에서 1 사이로 정규화하여 출력값의 총합을 항상 1로 만든다. 즉, K개의 클래스가 있을 때 각 클래스로 분류될 확률 출력
Dropout
- 인공신경망은 Layer와 Nod가 많아질수록 모델이 복잡해져 Ovefitting이 일어날 수 있음
- Dropout 은 과적합을 방지하는 Regularization과 모델을 Ensemble
- Node를 끄면 연결된 가중치가 사용되지 않으므로 학습할 Parameter 수가 줄면서 일반화된 모델 생성 가능
- 각 배치를 학습할 때마다 랜덤하게 Node가 선택되기 때문에 특정 조합에 너무 의존적으로 학습되는 것을 방지하며, 인공신경망을 앙상블하여 사용하는 것 같은 효과를 줌

Batch Normalization
- 여러 개의 은닉층을 통과하면서 입력 분포가 매번 변화하는 문제를 Internal Covariance Shift
- 학습 과정을 불안정하게 하여 가중치가 엉뚱한 방향으로 Update 되는 원인
- Batch Normalization 은 각 Layer 에서 Activation Function 을 통과하기 전 정규화를 통해 활성 함수 이후에도 어느 정도 일정한 분포가 생성되도록 하여 Internal Covariance Shift 해결
- 활성 함수의 비선형성이 반영되지 않기 때문에 Scale(y)과 Shift(B) Parameter를 통해 최적의 분포로 한 번 더 변환하여 활성 함수 통과
- 학습과 예측 과정에서 다르게 수행됨
- 예측 과정에서는 데이터가 개별로 들어올 수도 있고 테스트 데이터에 따라 평균과 분산이 매번 달라지기 때문에 테스트 데이터의 평균과 분산을 사용하지 않음
- 각 반복 학습 과정에서 구한 평균과 분산을 이동 평균을 통해 저장해 두었다가 예측 단계에서 사용
- 이유는 랜덤으로 초기화된 가중치로 인한 불안정한 단계보다는 학습이 어느 정도 지나 안정 단계의 평균과 분산을 더 반영하기 위함

고급 딥러닝 기술
CNN (Convolutional Neural Network)
- CNN은 이미지나 영상을 다루는 Computer Vision에서 가장 대표적으로 사용되는 인공신경망
- 정형 데이터는 데이터베이스 시스템의 테이블과 같이 고정된 Column 과 Observation(객체) 의 관계로 구성되어있음.
- Image는 사람의 눈으로는 한 장의 사진처럼 보이지만 컴퓨터가 읽을 때는 Pixel 단위의 숫자 행렬로 이루어짐.
- 다층 퍼셉트론의 입력층 Node 수는 정형 데이터의 입력 변수 개수와 같음.
- Image는 입력 변수라는 개념이 없음에도 불구하고, 정형 데이터로 바꾸기 위해서는 행렬을 1차원의 벡터로 펼처주어야 한다.
- Pixel 하나는 정형 데이터의 입력 변수 역할
- 행렬을 정형 데이터의 행으로 풀면서 이미지가 갖는 고유의 특성인 공간적 정보(Spatial Feature)를 잃어버리게 됨.
- Image를 정형 데이터로 변환하는 순간 행렬이 벡터로 변환되면서 공간적 정보가 사라지게 됨.
- 정형 데이터를 입력으로 받는 다층 퍼셉트론의 단점을 CNN은 이미지 그대로 입력을 받음으로써 극복할 수 있음.
CNN 구조
- Convolutional Layer : 이미지의 공간적 정보를 학습
- Pooling Layer : Convolutional Layer의 차원 형태의 크기를 줄임으로써 학습 Parameter 개수를 감소
- Fully Connected Layer : 최종 출력을 위한 다층 퍼셉트론 구조
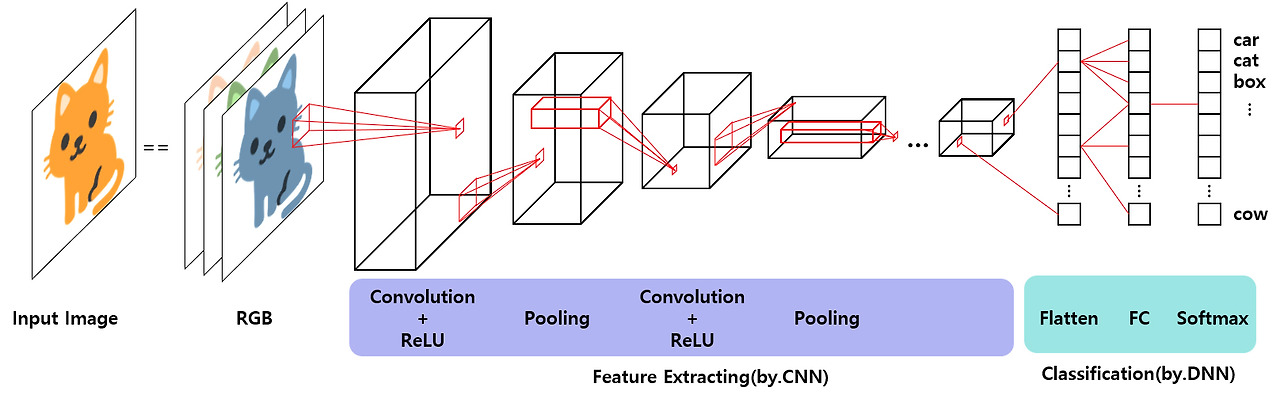
Convlutional Layer
- CNN에서 가장 핵심이 되는 부분으로 이미지의 중요한 지역 정보(Region Feature)를 뽑는 역할
- Image에 Filter(또는 Kernel)를 적용하여 Convolution(합성곱 연산)을 수행함.
- Filter가 입력 이미지를 훑으면서 겹치는 부분의 각 원소를 곱하여 모두 더한 값을 출력하는 연산

- Filter가 적용되는 음영 영역을 Receptive Field 라고 하고, 이 합성곱 연산을 통해 나온 행렬을 Feature Map
- Filter는 CNN에서 학습할 가중치로써 다층 퍼셉트론과 마찬가지로 초기에는 랜덤으로 주어지며 Loss Function가 줄어드는 방향으로 학습
- CNN 내부에서는 다양한 Filter를 적용한 Feature Map으로 이미지의 여러 정보를 결합하여 분류를 잘하도록 학습이 진행
- HyperParameter로는 Filter의 크기, Stride와 Padding 사용 여부가 있음
- Filter 크기 : Filter 높이와 너비
- Stride : Filter를 움직이는 간격
- Padding : Convolution을 수행하면 크기가 줄어드는 것을 방지하고자 입력 이미지 외각에 임의의 값(0 또는 이미지의 최외각과 동일한 값)을 부여하는 기술
- Stride : Filter가 입력 이미지를 순회할 때 움직이는 단위
- Stride가 클수록 Feature Map은 작아지므로 CNN을 구현할 때 주로 Stride = 1로 설정
- Padding으로 이미지 가장자리에 임의의 값이 설정된 픽셀을 추가함으로써 입력 이미지와 Feature Map의 크기를 같게 만듬.
Pooling Layer
- Convolutional Layer로 계산된 Feature Map의 크기를 줄여 연산량을 줄이는 역할
- 대표적인 방법 : Max Pooling, Average Pooling으로 최대 또는 평균을 취함
- Pooling Layer는 인접한 픽셀 중 중요한 정보만 남기는 강조 효과, 단순 계산만 진행하기 때문에 학습할 가중치가 따로 없음
- Convolution Layer에 적용할 필요는 없으며 선택 사항임.

Fully Connected Layer
- CNN은 회귀, 분류 모두에 적용할 수 있으며 다층 퍼셉트론과 마찬가지로 최종 출력값은 분류 문제이면 각 클래스에 대한 예측 확률 벡터, 회귀 문제면 예측값 벡터임.
- 고차원의 Feature Map이 출력값의 형태인 1차원 벡터로 변환되기 위해 Flatten Layer를 거치게 됨.
- Fully Connected Layer는 Flatten Layer를 통과한 벡터를 출력값의 길이로 변환시키는 역할
- Layer를 많이 쌓는 것은 Overfitting 및 학습 속도를 늦추는 원인이 됨.
Recurrent Neural Network (RNN)
- RNN은 Speech Recognition, NLP과 같이 순차적 데이터에 사용되는 대표적인 Algorithm으로, LSTM (Long Short-Term Memory)와 Gated Recurrent Unit (GRU)의 근간이 되는 모델
- 인공신경망과 CNN은 Feed-forward Neural Network.
- RNN은 Tanh Function Activation Function 을 사용하여 다음과 같이 표현.
- 은닉층으로 구한 값은 문제의 목적에 맞는 활성 함수를 적용하여 최종 출력값으로 반환
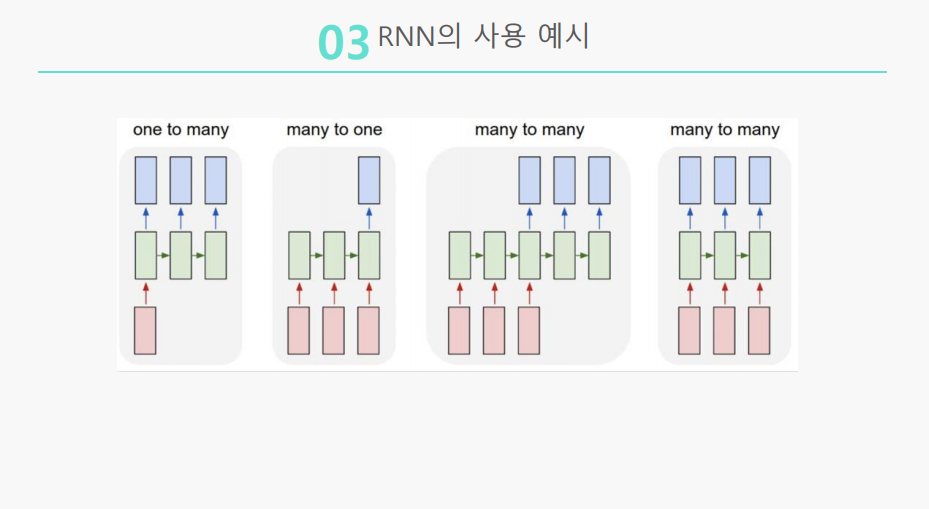
- One to Many : Image Captioning (이미지를 설명할 수 있는 문장을 생성하는 문제)
- Many to One : Sentiment Classification (텍스트에서 정보를 추출하여 감정, 태도를 파악하는 감성 분석)
- Many to Many : 동영상의 각 이미지 프레임별 분류
- Delayed Many to Many : Machine Translation (입력된 언어를 다른 언어로 변환하는 기계 번역)
Long Short-Term Memory (LSTM)
- RNN에서 입력과 출력 시점이 멀어질수록 학습이 잘 안되는 현상 : Long-Term Dependency Problem
- 과거의 정보를 은닉층에 저장하는 것인데, 이로 인해 매 시점이 지날수록 가중치와 활성 함수가 누적되어 곱해지기 때문에 과거의 정보가 점점 잊혀지는 것.

- LSTM은 RNN 구조에 몇 가지 기능을 추가하여 Long-Term Dependency Problem 해결
- Forget Gate는 "과거 메모리를 얼마나 기억할 것인가"에 대한 의사결정을 해주는 Gate -> Sigmoid Function Activation Function 적용하여 0에서 1 사이의 값을 출력하는 Forget Gate 표현
- Input Gate는 "현재 정보를 과거 메모리에 얼마큼 더할 것인가"에 대한 의사결정을 하는 Gate -> Sigmoid Function과 Tanh Function Activation Function가 적용된 두 개의 Module
- Cell state는 Element-wise (원소별) 벡터 연산이 수행됨.
- Output Gate를 통해 현재 시점의 출력을 구함 -> Sigmoid Function Activation 함수를 적용
- 연산 속도가 느리다는 단점이 존재
Reinforcement Learning (강화 학습)
- 미지의 환경에서 Agent가 임의의 행동 (Action)을 했을 때 받는 Reward 통해 먼 미래의 누적 보상을 최대화하고자 어떠한 행동을 할 것인지를 학습하는 Algorithm

| 요소 | 정의 |
| 상태(State) | 에이전트가 처할 수 있는 상황 및 정보 |
| 행동(Action) | 에이전트가 취할 수 있는 행동 |
| 보상(Reward) | 에이전트가 행동을 선택했을 때, 환경으로부터 받는 보상값 |
| 할인율 (Discount Factor) | 미래 보상을 현재 보상 가치로 환산해주는 요소 |
- Agent : 시작점을 출발하여 여러 행동을 통해 특정 상태에 도달하게 될 것
- Reward Function : t 시점에서 Agent가 상태 s에서 행동 a를 취했을 때 받을 수 있는 즉각적인 보상의 기댓값
- State-Value Function : Agent가 t 시점일 때 상태 s에서의 가치, 즉 현재 상태에서 앞으로 일련의 행동을 시행하면 받을 수 있는 누적 보상의 기댓값
- Action-Value Function, Q-value : Agent가 t 시점의 상태 s에서 행동 a를 취했을 때, 앞으로 일련의 행동을 시행하면서 받을 수 있는 누적 보상 값의 기댓값, 상태-가치 함수에서 행동을 함께 고려한 함수
- 각 함수를 기댓값으로 구하는 이유는 State Transition Probability 가 고려되기 때문임.
- 모든 상태에 대해 Agent가 취할 행동을 정책(Policy, π) 라고 하며, 정책은 높은 가치 함수를 받는 방향으로 학습
- Agent는 최적 정책에 따라 행동하면 보상의 합을 최대로 받을 수 있음
- 단순하고 실제 환경(상태, 보상, 전이 확률 등)의 정보를 정확히 아는 경우는 거의 없음.
- 강화학습 기법 : Monte-Carlo Policy Evaluation (몬테카를로 정책 평가), Temporal Difference Policy (시간 차 학습), SARSA(살사), Q-Learning, Deep Reinforcement Learning
Generative Adversarial Networks (GAN)
- 데이터 생성이라는 새로운 분야
- 데이터를 모방하여 새로운 데이터를 만드는 것
- 두 개의 네트워크가 서로 목표를 달성하기 위해 적대적으로 겨루는 구조
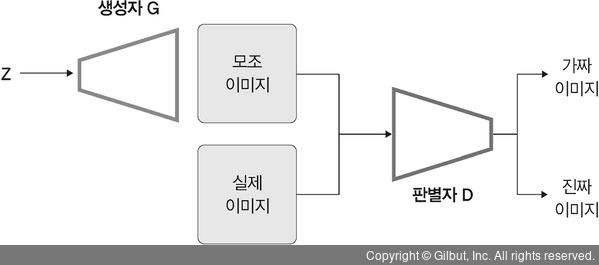
- Generator (생성모델) 과 Discriminator (분류모델)이 겨루는 Network
- Loss function은 Generator 와 Discriminator 의 상반된 목적을 풀기 위해 Minimax Problem 적용

- Generator : Random noize z로 만들어낸 가짜 데이터 G(z)를 생성하여 가짜 데이터를 진짜 데이터로 분류할 확률 D(G(z))를 높게 예측하는 것
- Discriminator
1) 실제 데이터 x를 입력받아 진짜 데이터로 분류할 확률 D(x)를 높게 예측하는 것
2) Generator가 만든 가짜 데이터 G(z)를 입력받아 진짜 데이터일 화귤 D(G(z))를 낮게 예측하는 것
- Generator는 Loss function을 최소화하고 Discriminator는 최대화하는 방향으로 적대적으로 학습
'Data Engineer > AI' 카테고리의 다른 글
| AI - 작물 잎 사진으로 질병 분류 (3) | 2024.11.16 |
|---|---|
| AI - Pytorch (6) | 2024.11.14 |
| AI - ChatGPT API (Day 2) (4) | 2024.11.11 |
| AI - ChatGPT API (Day 1) (4) | 2024.11.10 |
| AI - ML (3) | 2024.11.05 |