

Topics
- 텍스트 마이닝이란
- 텍스트 마이닝의 절차
- 텍스트 마이닝의 사례
텍스트 마이닝이란
텍스트 데이터 (Text data)
- 문자, 문장, 단어로 구성된 데이터
- 대규모 데이터는 매일 약 8200만 TB의 텍스트가 생성되는데, 그 중에서 text만 추출한 것
- 텍스트 데이터를 통해 시장 변화를 파악하고 대응하거나, 고객의 요구사항과 feedback을 파악할 수 있음

텍스트 데이터의 특징
- 텍스트 데이터를 구성하는 요소 (문장, 문자, 단어) 에서 단어는 주변의 단어들과 연관성이 존재하는데, 이 연관성을 이해하는 방향으로 텍스트 데이터를 처리하여야 함
- 텍스트 데이터를 처리하는 과정에서 어려움이 발생할 수 있음
1. 비구조적(비정형) 데이터
2. 다양성, 다의성이 존재함
3. 언어별로 고유한 특징이 존재 (문법, 어휘, 발음 등)
텍스트 마이닝이란
마이닝 (Mining, 채굴)
- 채굴이란 단어의 의미는 광물에서 귀중한 금속이나 광석을 채굴하는 작업을 의미
- 대량의 데이터(광물) 에서 유용한 정보와 패턴(자원) 을 찾기 위해 채굴이 필요한데, 여기서 얻어낸 정보와 패턴으로 통찰력을 얻고 의사 결정을 진행함
- 즉, 데이터로부터 "의사 결정"을 하기 위해 Mining 을 진행함
- 원천 데이터가 어떠한 데이터이냐에 따라서 마이닝의 종류가 달라짐

텍스트 마이닝 (Text Mining)
- 대용량의 텍스트 안에 존재하는 관계, 패턴, 규칙을 탐색하여 지식과 인사이트를 추출하여 의사 결정에 활용하는 일련의 과정
 |
 |
텍스트 전처리 | 텍스트 마이닝 | 해석 및 평가 |
자연어 처리 (Natural Language Processing, NLP)
- 텍스트 마이닝과 같다고 생각하지만, 다른 점이 존재함 (NLP : 언어의 이해, TM : 언어 속에 내포된 정보를 파악)
- 컴퓨터가 인간의 언어를 이해하고 해석하는 데 사용되는 분야
- NLP의 목적은 글을 활용한 문제를 해결하고 더 나은 사용자 경험을 제공하고자 함

텍스트 마이닝에 사용되는 패키지
- Python, R
- 텍스트 데이터 수집, 처리, 분석, 시각화 등 다양한 작업을 지원함
- Pandas : 텍스트 데이터 조작과 처리에 용이함
- Gensim : 전처리 과정인 embedding 과정 지원
- nltk : 자연어를 다루는 과정에서 유용한 tool kit 지원
텍스트 마이닝 절차
1️⃣ 텍스트 수집 및 추출
데이터 수집 방법
❶ 웹 크롤링
- 웹에 존재하는 텍스트 데이터를 수집 (Selenium, Beautiful soup, Scrapy 등 패키지를 활용)
- 크롤링 가능한 사이트를 위주로 사용하여야 함 (개인정보 보호 이슈)
❷ API 사용
- 대형 SNS Platform (ex - Instagram, Facebook), 뉴스 사이트 등 데이터 제공을 위한 API 제공
- API 사용 비용을 지불해야 할 수 있음
❸ 공개 데이터
- 연구 기관, 정부 기관, 기업 등에서 제공하는 공개 데이터 활용
원시 데이터로 쓸 수 없는 형태의 데이터 ("ㅋㅋㅋ..", 이모티콘)도 존재하므로 데이터의 품질을 관리하기 위해 사용 목표에 맞는 데이터를 주기적으로 모니터링하여야 함.
2️⃣ 텍스트 전처리
- 수집된 텍스트 데이터는 비구조적(비정형) 데이터가 일반적이므로 전처리 과정을 통해서 데이터를 정제하고 분석이 가능한 형태로 변환하여야 함
- 텍스트 전처리는 풀어야 하는 문제에 따라 다양한 방법들이 존재함
❶ 노이즈 값 제거
- 원시 데이터에는 이모티콘, 오타, 비속어 등 다양한 노이즈 값이 존재하는데, 이러한 이상 데이터를 제거
- 의미가 있는 경우에는 데이터를 수정
❷ 분석에 최소 단위로 글을 분류
- 단어 기반 문제 풀이, 문장 기반 문제 풀이 등에 따라 사용하는 정보의 단위(Token)가 다름
- Token 단위로 글을 분리해야 함 (Tokenize)
- 컴퓨터가 이해할 수 있는 형태로 변환하여야 함 (Embedding)
❸ 글 길이 조절
- 제한된 환경에서 작성된 글이 아닌 경우, 너무 길거나 짧은 글이 존재하는데, 이를 통일된 형태로 변경해야 함
- 만일 글이 길다면 자르고, 짧다면 복제 혹은 다른 글과 통합 또는 dummy 값을 추가함
3️⃣ 텍스트 마이닝 기법 적용
- 데이터로부터 유의미한 정보를 추출하고, 인사이트를 도출하는 과정
❶ 내용 파악 및 분석
- 자연어 이해 : 글에 존재하는 의미와 의도를 파악
- 요약
- 개체명 인식 : 글에서 인물, 장소, 기관 등의 특정 정보를 식별 & 분류
❷ 숨겨진 의미 파악
- Topic modeling : 글에 담겨있는 숨겨진 주제를 발견
- Trend 분석 : 시간에 따른 데이터 변화를 분석, 패턴과 변화를 분석
- 감정 분석 : 글에 존재하는 저자의 감정 상태를 파악
❸ 관계 파악 및 구조화
- 군집화 : 비슷한 의미의 글을 그룹화하여 문서 간의 관계 파악
- 글 분류 : 글을 특정 범주로 분류
4️⃣ 텍스트 마이닝 결과 분석
- 분석된 결과를 활용하여 정보 이해, 통찰 도출, 의사 결정 과정에서 사용
❶ 정보 이해
- 텍스트의 전반적인 내용 파악
- 타겟 그룹에서 생성된 글의 패턴과 흐름을 빠르게 확인
- ex) 제품을 사용하는 사용자 중 40대의 반응을 보고 제품 사용 관점에서 나오는 keyword 파악 (keyword 의미를 분석하는 것은 데이터 분석 과정)
❷ 통찰 도출
- 데이터 안에 숨어 있는 연결 정보를 추출
- 숨은 정보를 추출하는 기술적 모델 필요
- ex) 제품에 대한 긍정적인 포인트와 부정적인 포인트 이해
❸ 의사 결정
- 통찰을 바탕으로 비즈니스 전략, 제품 개발, 마케팅 등의 의사 결정 과정에서 사용
- ex) 부정적인 부분을 개발하고, 이를 적극적으로 마케팅에 활용
텍스트 마이닝의 사례
1️⃣ 자주 묻는 질문 (FAQ)
- 자주 묻는 질문과 그에 대한 답변을 모아 놓은 목록
- 사용자가 자주 겪는 문제나 궁금증을 빠르게 해결할 수 있도록 도움
- CS, 고객 피드백, 리뷰 등에서 수집된 질문 - 답변 패턴 식별 및 분석
- 지속적인 업데이트로 서비스를 개선
- 사용자는 빠른 문제 해결과 편리한 정보 접근이 가능
- 서비스 제공자는 고객 지원 비용 절감 및 고객 만족도 향상 효과를 얻을 수 있음

2️⃣ 책에 밑줄 긋기
- 중요한 내용이 무엇인지 판단
- 목적에 맞는 밑줄 긋기가 필요
- 독자는 중요한 정보를 빠르게 시각화할 수 있고, 기억력 강화를 통해 정보 정리를 효과적으로 진행
3️⃣ 심리 분석
- 환자로부터 나온 글 내용 속 단어, 문구, 분위기를 바탕으로 심리 상태, 감정 변화, 중요한 사건이나 생각 패턴을 파악
- 디지털화된 데이터(일기, 전화 내용, 상담 내용 등) 내에 존재하는 환자의 감정 상태를 파악
- 그래프와 차트 형태의 시각화 과정으로 빠른 파악 가능
- 환자 입장에서 본인의 상태를 깊게 파악할 수 있고 맞춤화 치료 과정을 진행할 수 있음
- 상담사의 입장에서는 상담의 효과를 향상시킬 수 있고 환자의 상태를 정량적으로 확인하고 치료 과정의 변화를 확인할 수 있음

4️⃣ 신문 스크래핑
- 관심 있는 주제와 관련된 내용을 인식하는 과정이 필요함 (특정 개체 이름, 관심 이슈 등)
- 구독자는 최신 데이터를 추적할 수 있고 관심 분야의 패턴을 확인할 수 있음
- 시간에 따른 의미 관계 파악, 언론사 별로 바라보는 여러 시각 정리 및 다양한 관점을 습득 가능
- 투자, 사업성 등 다양한 관점의 의사 결정을 내릴 수 있음
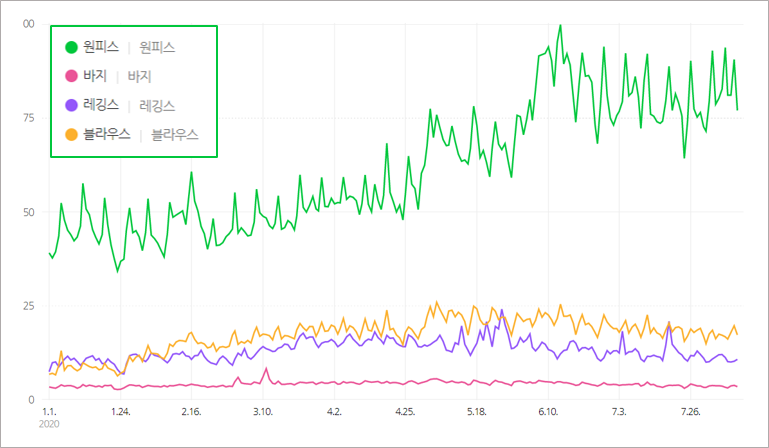
5️⃣ 네이버 검색 트렌드
- 검색어 단어의 발현 횟수를 기반으로 트렌드 확인
- 사람들의 관심사, 전 국민적 이슈 등을 파악 가능
- 특정 단어에 대한 사람들의 관심사 파악
- 제품 판매 및 예측을 미리 예측해볼 수 있음
- 비즈니스의 의사 결정에 활용될 수 있음
'Bootcamp' 카테고리의 다른 글
| [Week 14] Day 3 - TIL (1) | 2024.03.05 |
|---|---|
| [Week 14] Day 2 - TIL (1) | 2024.02.28 |
| [Week 11] Day 2 - TIL (1) | 2024.02.06 |
| [Week 11] Day 1 - TIL (0) | 2024.02.05 |
| [Week 10] Day 1 - TIL (2) | 2024.02.05 |